이미지 인식 인공지능을 활용한 접근성 개선 예시
안녕하세요. 엔비전스입니다.
최근 들어 인공지능 기술이 발달함에 있어 AI 기술들의 활용도가 증가하고 있습니다.
일반적인 활용의 예시를 들어 보겠습니다. 만약 이미지 인식 AI를 사용하면 오프라인 CCTV에 잡힌 구매자의 나이를 인공지능을 통해 유추하여 소비자들의 연령층을 분석해 각각의 상품에 대한 관련 데이터를 쌓을 수 있습니다. 조금 더 가까이에서 접할 수 있을 만한 기능으로는 갤러리 내 사진 분류가 있습니다. 따로 지정해 놓은 설정이 있는 것도 아닌데 비슷한 인물별로 앨범을 정리해 주거나, 똑같은 사진을 찾아 중복되는 이미지를 삭제할 수 있도록 도와주는 기능들을 접해 보셨거나, 들어 보신 적이 있을 거라 생각합니다. 이는 모두 이미지 인식을 통한 활용의 예시가 될 수 있습니다.
이렇듯 실생활에서 이미 어느 정도 영향을 주고 있는 기능이지만, 개중에는 이런 이미지 인식 기능을 시각 장애인들의 접근성 개선을 위해 제공된 사례들이 몇 가지 있습니다. 오늘은 이에 대해 간단히 살펴보겠습니다.
우선 이 이미지 인식에 들어가기 앞서 이와 같은 과정에서 가장 기본이 되는 기술에 OCR이 있습니다. 관련 내용을 이전 아티클에서 언급을 통해 아주 간단히 다룬 적이 있는데요. OCR이란, Optical Character Reader의 약자로, 이미지 내 글자를 인식하여 텍스트 데이터로 변환시켜 주는 광학인식 기술을 말합니다. 외국어가 적혀 있는 사물의 사진을 찍어 해당 사물에서 텍스트만을 추출해 번역을 하는 기능을 보신 적이 있을 것 같습니다. OCR은 이미 많은 웹사이트와 애플리케이션에 통용되고 있는 기술로 가장 쉽게 접할 수 있는 접근성 기술 중에 하나이기도 합니다.
최근에는 기존에 이미지 파일로 이루어져 시각 장애인들이 접근할 수 없었던 상품 상세 영역에 이 OCR 기능을 사용하여 시각 장애인들의 접근성을 높이는 시도가 여러 쇼핑 사이트에서도 이루어지고 있습니다. 다만 대부분의 상품 상세 영역에는 상품의 이미지 역시 들어가 있기 때문에, 만약 별도의 대체 텍스트가 제공돼 있지 않은 상품 상세 영역에 OCR 기능만을 사용한다면 시각 장애인들은 상품의 상세 정보를 텍스트로 인식할 수 있어지는 대신, 이미지에 대한 정보는 여전히 제공받지 못하는 한계점이 존재합니다. 때문에 조금 더 가능성이 있는 접근성을 제공하기 위해 이미지 인식 인공지능을 활용할 수 있습니다.
관련 기능을 사용하는 앱을 통해 기술의 예시를 보겠습니다.

해당 사진을 각각의 앱에서 이미지 인식을 통해 살펴보겠습니다.

대표적인 시각 장애인을 위한 앱 중 하나인 설리번+ 앱 내에서 해당 사진에 이미지 묘사 기능을 써 봤습니다.
첫 번째 시도에서 나온 이미지 묘사 텍스트는 해당 이미지의 분위기를 전체적으로 유사하게 설명했으나 “작은 전자 장치”와 같이 구체적인 설명력이 다소 떨어지는 부분이 있습니다.

동작을 한 번 더 시도해 보았습니다. 이번에는 키보드 위에 올려져 있는 “리모컨”을 제대로 인식했습니다. 방금 전과 다르게 조금 더 구체적인 단어로 이미지가 묘사되었지만 이번에도 역시 키보드와 리모컨을 분리하여 인식하지는 못했습니다.
한 가지 앱을 더 사용해 보겠습니다.

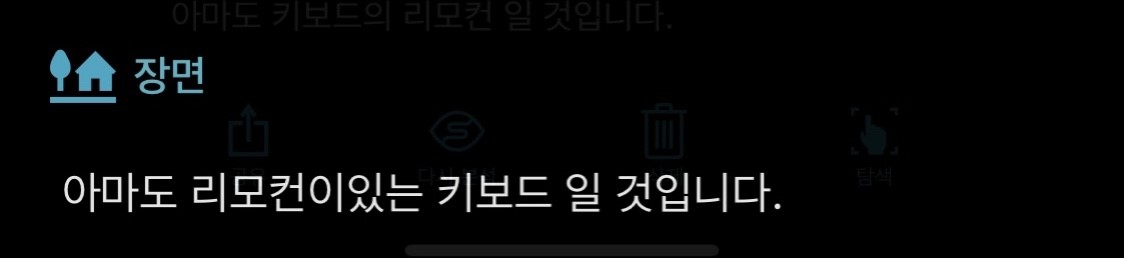
역시 시각 장애인을 위한 개발된 Seeing 앱입니다. 설리반+와 마찬가지로 두 번 시도한 끝에 문장이 조금 더 정리된 것이 보입니다. 이번에는 리모컨과 키보드를 분리하여 인식했습니다. 하지만 여기서도 역시 리모컨과 키보드의 위치를 분리한 설명이 덧붙여지지는 못했습니다.
이는 인공지능이 인식하는 범위의 한계점을 보여 주기도 합니다. 예시 사진 내에서와 마찬가지로 대부분의 이미지 인식 기능에서는 인식률이 떨어질 경우“아마도”라는 유추 가능성을 사용자에게 덧붙여 설명하는 경우가 많습니다. 이렇게 인식을 하였으나, 아닐 수도 있다는 가능성 역시 제공해 주는 셈입니다. 이미지를 온전히 음성으로 설명 받아야 하는 사용자의 입장에서 인공지능의 인식을 완벽히 신뢰할 수 없다는 점은 분명 한계점이 존재하지만, 시각적으로만 가능한 이미지 인식에 대해 유추할 수 있는 기회, 해당 유추 결과에 대해 신뢰할지에 대한 선택지를 제공한다는 점은 분명히 접근성에 있어 활용도에 대한 기대치가 높은 기술일 수 있습니다.
같은 사진을 비슷한 이미지 인식 인공지능을 활용하는 네이버 스마트렌즈를 통해 보게 된다면 어떨까요.
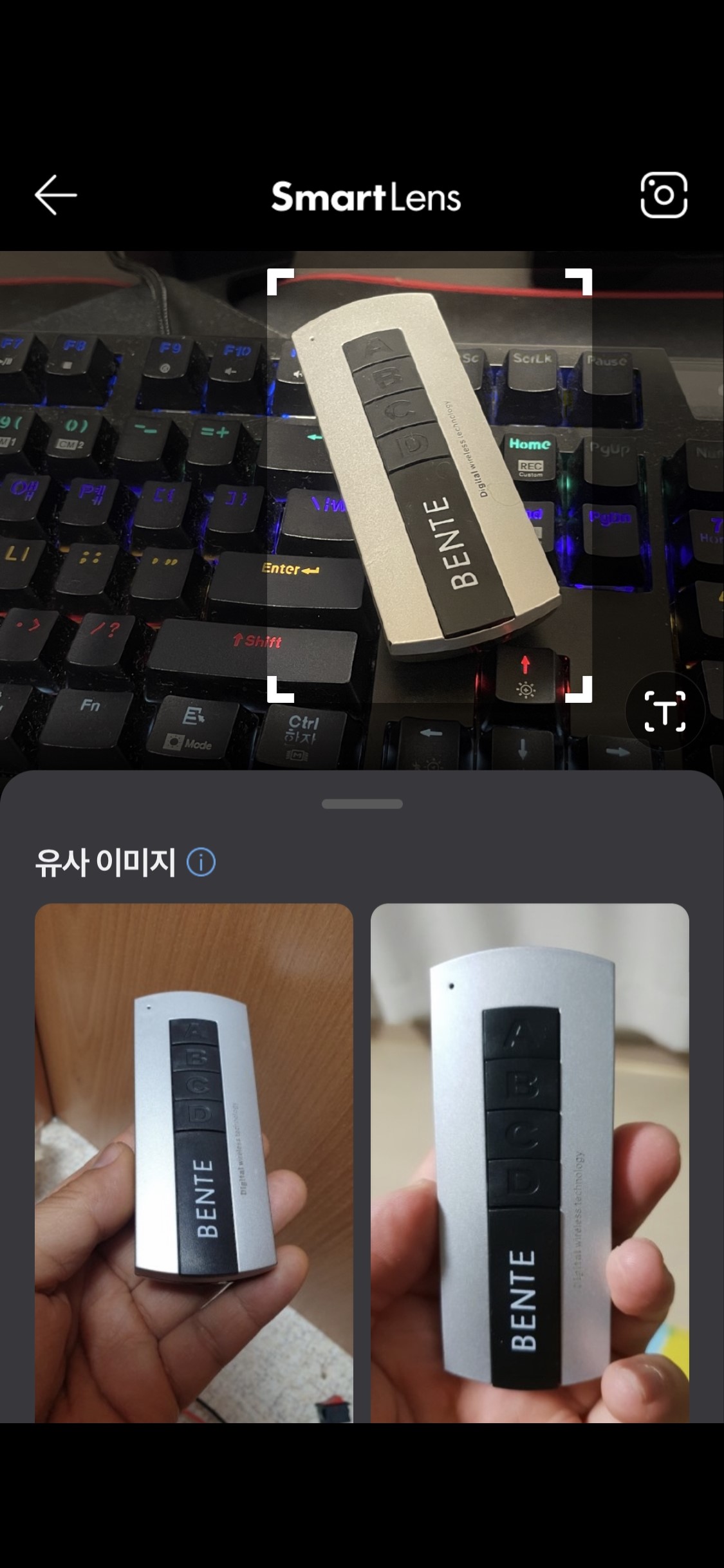
사진과 같이, 여기서는 이미지에 대한 구체적인 묘사가 나오지는 않는 대신 해당 이미지와 흡사한 사진을 검색을 통해 찾아 줍니다. 예시 사진에서는 키보드 위에 올려져 있던 리모컨의 이미지만을 따로 정확히 분리하여 똑같은 이미지 결과를 찾아내 높은 정확도를 보이고 있습니다. 이는 사진의 퀄리티 혹은 구도에 따라 검색되는 이미지와의 유사성이 달라질 수 있는데, 이를 시각 장애인 입장에서는 분간이 불가능한 점이 역시 다소 아쉬운 점으로 꼽을 수 있겠습니다. 다만 이런 이미지 검색 기능의 경우 해당 유사 이미지가 포함된 블로그와 같은 게시글에서 조금 더 광범위한 검색 결과를 제공받을 수 있기 때문에 이 역시 시각 장애인에게 이미지를 통한 인식에 더 넓은 데이터와 가능성을 제공해 주는 기능이 될 수 있습니다.
위에서 본 애플리케이션의 경우 사용자가 직접 카메라에 이미지를 인식시키거나 갤러리를 통해 이미지를 삽입해야만 적용이 가능하다는 한계점이 존재하는데요. 사용자가 직접 탐색 중인 사이트에서 곧바로 이미지 인식 인공지능을 접해 적용시킬 수 있는 기능 중에는 Chorme의 “이미지 설명 가져오기”가 있습니다.
Chorme 설정 > 고급 > 접근성 페이지 내에서 “Google에서 이미지 설명 가져오기”
간단한 경로를 통해 해당 기능을 동작시켜 놓는다면 Chrome 내에서 탐색 중인 페이지 내에 대체 텍스트가 없는 이미지가 있는 경우 인공지능이 해당 이미지를 분석해 임의로 대체 텍스트를 삽입해 주게 됩니다. 이는 스크린 리더 사용자나 점자 기기를 사용하는 시각 장애인의 한에서 들을 수 있는 정보입니다. 인공지능을 통해서도 분간할 수 없는 이미지라면 “설명이 없습니다”라는 문구를 말하며 정확도가 떨어질 수 있는 대체 텍스트에는 “~같습니다” “아마도” “~일 수 있습니다”와 같이 가능성 여부 역시 제공됩니다.
현재로서 존재하는 이미지 인식 기능들은 개별적으로도 분명히 시각 장애인들의 접근성에 도움이 되는 기능들이지만 아쉬운 점 역시 여럿 드러나는 것이 사실입니다. 해당 기능들을 사용하고 있는 서비스들의 목적이 각각 다르기 때문에 앞서 보여 드린 것처럼 활용성에서도 어딘가에 하나씩 제한점이 존재합니다. 해당 기능들을 잘 활용한다면 지금보다도 나은 접근성 개선 사례가 나타날 수 있을 거라 생각합니다.
다만 접근성을 제공하는 입장에서는 이와 같은 이미지 인식 인공지능에 대한 활용도는 높이되 지나치게 의존하지 않는 것 역시 중요할 것입니다. 시각 장애인은 해당 인공지능이 유추하는 이미지 정보의 정확도를 개인이 직접 분별할 수 없기 때문에 이를 활용한 정보 제공이 지나치게 많아진다면 이 역시 정보를 분별하는 데 있어 문제가 될 수 있습니다. 이를 적절히 어떻게 섞어 사용하느냐에 따라 접근성의 한계점이 달라질 수 있을 것입니다.
인공지능은 받아들인 정보의 양에 따라 분석력이 올라가는 데이터 기반 시스템입니다. 이는 근래에 카메라 기능을 탑재한 기기의 사용량들이 많아지면서 실생활에 이미지 인식 인공지능의 활용도가 높아진 것에 대한 이유가 되기도 하는데요. 시각적으로 이미지를 확인할 수 없는 시각 장애인이 이미지를 통해 정보를 제공받는다는 것은 어떻게 보면 아이러니한 일일 수 있지만 이와 같은 기능들은 시각 장애인에게 정보를 제공받을 수 있는 중요한 수단 중에 하나가 되기도 합니다. 관련 기능을 활용한 접근성에 대한 연구가 꾸준히 필요할 것입니다. 읽어 주셔서 감사합니다.